Введение. Для ознакомления с состоянием дел по проблемам искусственного интеллекта (ИИ) можно посмотреть фундаментальный обзор 2003 года в 860 страниц [11], отметим, что этот обзор содержательно повторяет книгу "Системы искусственного интеллекта" Ж.-Л.Лорье 1987 года (русский перевод в 1991 году), некоторые значительные фрагменты полностью тождественны. Это характерно для всей области автоматизации интеллектуальной деятельности. За полтора десятилетия в разрешении "основного вопроса философии" ни теоретически, ни практически не было сделано ни одного серьезного шага вперед. Хотя, наверняка, будущие историографы науки найдут в работах ученых XX века разрозненные фрагменты работ, объединение которых позволило бы уже несколько десятилетий назад нашей цивилизации пользоваться плодами ИИ, но торопливость разработчиков и эгоизм политиков не позволили организовать фундаментальное наступление на наше незнание об окружающем нас мире. В одиночку и малыми силами проблему построения ИИ всеохватывающей сложности полномасштабно не решить, учитывая психофизиологическую ресурсную ограниченность человека (скорость биологической элементной базы ~ десятки Гц, объем памяти ~ Мегаобразы, максимальное число параллельных процессов ~ 2-3.). С другой стороны, видны масштабы открывающихся перспектив интеллектуализации нашей цивилизации с появлением ИИ (скорости электронной элементной базы ~ гигагерцы, объем памяти ~ практически не ограничен, число параллельных процессов ~ тысячи и миллионы). И особенно сегодня, во времена стихийного, как из ящика Пандоры, появления различных технологий глобального воздействия (ядерных, био-, информационных и пр.), порождающих "сотни тысяч" проблем, отсутствие функционирующего ИИ с его неограниченной интеллектуальной мощностью ставит под сомнение дальнейшее существование нашей цивилизации уже к середине XXI века. Проведенный нашей группой анализ теоретических наработок в области нейрокомпьютинга и искусственного интеллекта показывает их сегодняшнюю достаточность для формирования технического задания на построение искусственного разума (ИP). Появившиеся за последние полувека новые данные нейрофизиологии, лингвистики, психологии, computer science и других смежных дисциплин позволяют концептуально увидеть проект ИP, который по функциональным и количественным характеристикам будет превосходить биологический прототип. Стало понятно, что в основе становления ИP должно быть положено ограниченное число простых принципов, которые были бы способны его саморазвивать эволюционным путем. Наша группа предлагает рассмотреть тезисы проекта построения ИP на основе нейросемантической парадигмы. Основная цель предварительных обсуждений представленных тезисов, выявление возможных их концептуальных несоответствий заявленной задаче (инженерное задание по проектированию ИР). Проект находится в стадии разработки, и подробное формальное ознакомление с ним, его разделами (механизм эволюции, природа информации, текстовая энтропия, информационная система и пр.) будет проведено в Институте проблем управления РАН в ближайшие месяцы. Цель обсуждения - выявление возможных некорректностей предлагаемого проекта в современной научной парадигме или неполноты его изложения в рамках поставленной задачи как инженерного проекта построения ИР. 1. Зарождение и механизмы направленности эволюции простейших информационных систем (ИС). В качестве модели среды зарождения ИС предположим, что первоначальный "Большой символьный взрыв" порождает множество символов "а" алфавита А (a,b,c,d,…,w,x,y - аналоги химических элементов и z - как аналог пространства). Далее символы в соответствии со своим "полупериодом синтеза" начинают эволюционировать в тексты (a → bb → bccz; bb→ccccz; ccb→ddcbz; …). В результате порождается "текстовой бульон". Известно, что простейшие компьютерные вирусы состоят из нескольких сотен байт. Следовательно, таким случайным образом могут сформироваться простейшие самодублирующиеся ИС, которые за счет дальнейших мутаций могут начать эволюционный процесс в "символьной среде" ("текстовая жизнь"). 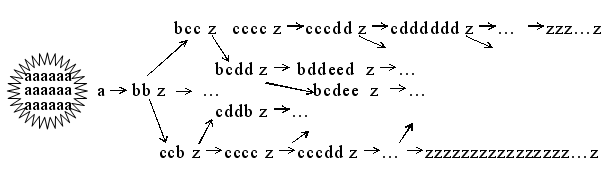 Рис. 1.
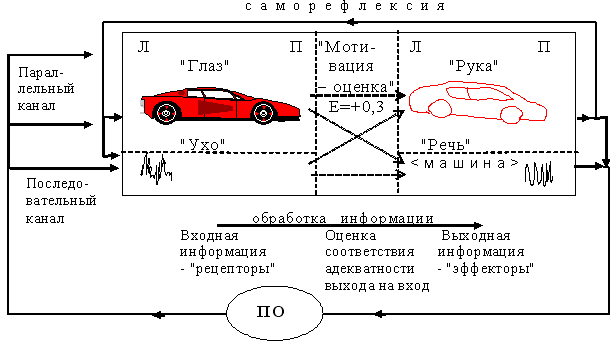
Для оценки скорости экспансии ИС предлагается структура простейшей обобщенной самодублирующейся ИС (см. рис. 2) и формальное описание окружающей её среды (предметной области – ПО). При этом тексты среды рассматриваются одновременно: как строительный материал, как носитель энергетического ресурса (a>b>c>d>…>w>x>y>z=0) и как источник упреждающей информации. 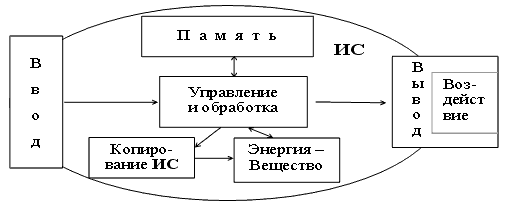 Рис. 2.
Первый эволюционный аттрактор ИС – "рецепторный". Он выражается в тенденции к расширению диапазона рецепторного окна ИС, т.к. при линейном увеличении размеров окна (L длины воспринимаемых текстов через "Ввод", см. рис. 2) разнообразие и количество воспринимаемых текстов увеличивается в степенной функции, как AL, где А – алфавит текстов (см. рис. 3). 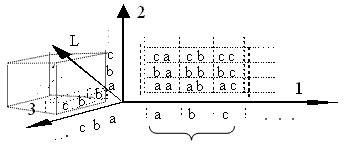 Рис. 3.
Если бы, например, в ИС эволюционировал блок "Выводы – воздействие" (см. рис. 2), увеличившись в n-раз, то при неограниченности ресурсов ПО, количество воспринимаемых текстов через "Ввод" могло бы возрасти, но только не более чем в n-раз, т.е. не более чем линейно. Поэтому на первых эволюционных ступенях первоочередность развития в ИС "рецепторного" блока очевидна. Это наглядный пример безальтернативности эволюции ИС через этапы эволюционных аттракторов. Первый эволюционный аттрактор ИС – это пример положительной обратной связи, приводящий к экспоненциальному взрыву численности ИС, с естественной вынужденной последующей длительной стабилизацией при использовании всего энерго-вещественного ресурса ниши. А это уже пример отрицательной обратной связи. Т.е., положительная обратная связь – революционный скачок эволюционного развития, и отрицательная обратная связь – эволюционный консерватизм. Чем больше у ИС возможностей прогнозируемо получать энерго-вещественный ресурс, тем больше её эволюционный потенциал [2]. Величина эволюционного потенциала ИС измеряется в единицах располагаемой ею энергии и времени прогнозирования развития процессов. Будем считать, что при конкуренции за ресурс нескольких видов ИС всегда побеждает тот, у которого больший эволюционный потенциал. Численность вида самокопирующихся ИС для данной ПО пропорциональна их эволюционному потенциалу. На примере эволюции биологических ИС, рассматривая её текущего лидера (например, "венца творения"), можно проследить его эволюционную траекторию от самого "начала". При этом можно аналитически отследить решающие этапы (аттракторы) его конкурентной борьбы и причины сохранения эволюционного лидерства. Мы попытаемся провести эту работу, но уже в рамках нашей модели, выявив все эволюционно прогрессивные шесть аттракторов (как относительные нелинейности в характеристиках ПО). Кратко резюмируя материал этого раздела [2], отметим, что в нем:
2. Комплекс: "Предметная область – Информационный канал – Информационная система". Любую физическую ПО можно рассматривать как некоторую дискретную пространственно-временную область с взаимодействующими объектами (ai, aj, см. рис.4). При попадании нескольких объектов в область взаимодействия, происходит процесс их взаимодействия, выражающийся в некотором физическом процессе (см. рис. 5а). 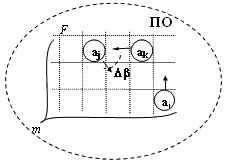 Процесс взаимодействия объектов осуществляется в течение нескольких тактов времени t2 - t1 (такт времени, – это минимальная измеряемая ИС физическая дискретность времени, ее квант). Результат взаимодействия объектов выражается в изменении величины вектора параметров (W), характеризующих этот процесс. Процесс изменения одной из компонент вектора (Wi) может быть преобразован в текстовую форму, см. рис. 5.  Рис. 5.
Амплитуда изменения параметров процесса отображается в некотором алфавите А={a, b, c, …, z} с первоначальной физически допускаемой дискретизацией ΔW = W / |A|, а число символов отображаемого процесса определяется его длительностью t2 - t1 и дискретизацией по времени ΔDt. Очевидно, что произвольный физический процесс любой мерности (графической, акустической, текстовой и т.д.), можно взаимнооднозначно отобразить в текстовую форму (ТФ) и обратно, с любой наперед заданной степенью точности соответствия [3]. ТФ – это "цифровая" форма представления аналогового сигнала или "отекстовка" со всеми вытекающими из этого последствиями [3]. Таким образом, при анализе и моделировании ИС происходящих в ПО процессов, достаточно использования только текстовой формы (см. рис. 5г.), т.е. мы остаемся в рамках модели "текстовой жизни" (см. рис. 1). При взаимодействии объектов (например, {ai*aj}), в соответствии с F(ПО) (см. рис. 4), порождается ЭСЕ – элементарная семантическая единица (S{ai*aj} = <cade…b>), которая однозначно отображает процесс взаимодействия этих объектов, как "скрытых параметров" ПО. Все множество процессов, как совокупность ЭСЕ в данной ПО, представляет собой семантическое пространство – S (см. рис. 6.). В качестве разноуровневых примеров ЭСЕ различных ПО можно привести: а) взаимодействие элементарных частиц – <ababcw>; б) <Привет Петров, как дела? Нормально!> – взаимодействие объектов макроуровневых ПО; в) образование двойной звезды из двух астрообъектов – <zzjbaabj> (на гигауровне) [3] При анализе одновременного взаимодействия не более чем d объектов ("пар", "троек", … , "d", см. рис. 6.), мы получаем (фиксируем) d-мерный куб со стороной n (n равно числу типов на данный момент времени объектов ПО). В d-мерном кубе всевозможные одномоментные взаимодействия объектов {a1, a2, …, an} детерминировано отображаются множеством элементарных информационных единиц S ={s1, s2, …, su}, где u≤nd. 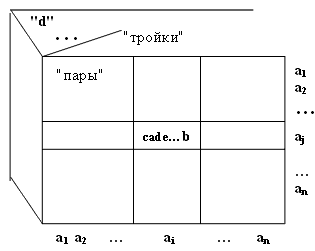 Рис. 6.
Если же в реальной ПО одновременно взаимодействуют d+1 или более объектов, а возможности анализа ИС не превышают d объектов, то получаем статистическое распределение ЭСЕ, например, < <abaacw><ababcw><abbbbw><abbbcw><abaccw> … <aaacww> >. Синтез новых объектов-процессов – это естественный эволюционный процесс. Он наблюдается, когда некоторые процессы принимают устойчивую форму объектов (эмерджентность) и тем самым расширяют сторону d-мерного куба: (n+1), (n+2), … (n → ∞). При этом мощность числа состояний d-мерного куба существенно превосходит число реализованных состояний ПО, т.е. (n+p)d >>Σ ПО(ЭСЕ) = ТФ. Поэтому детерминированной, или определенной, рассматривается ЭСЕ уже реализованная в ПО и отображенная в ИС. Порождаемые в ПО ЭСЕ суперпозиционно "сливаются" в непрерывный информационный поток (см. рис. 7,8 – информационный канал (ИК)). В ИК происходит процесс формирования информационного ресурса как в передающей субстанции между ПО и ИС. В отличие от ПО, в ИК осуществляется только суперпозиция и интерференция информационных компонент процессов, произошедших в ПО, и их транспортировка к ИС. Физическая плотность объектов и особенности законов F(ПО) определяют частоту происходящих в ПО процессов. Понятно, что при постепенном увеличении плотности объектов, сначала в среднем будет формироваться изолированное во времени следование ЭСЕ (см. рис. 7а), далее - слитное (см. рис. 7б) и до перекрытия в различной степени (см. рис. 7 в). 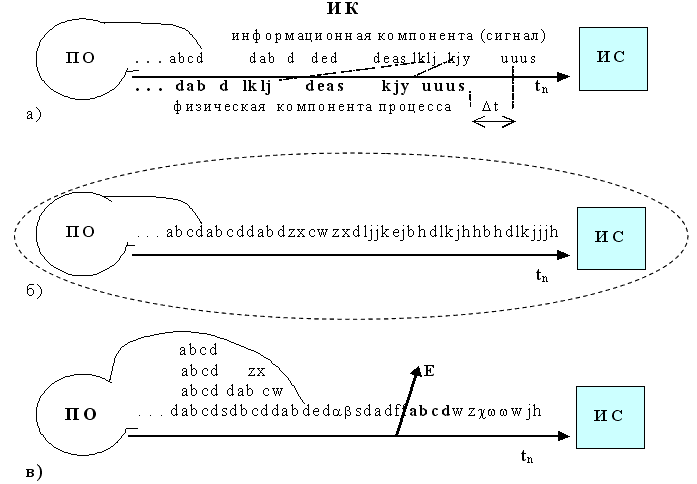 Рис. 7.
Эксперименты на тестовых ПО показали, что во всех трех случаях (см. рис. 7 а,б,в) ИС успешно выделяла ЭСЕ. Но в будущем, при теоретическом рассмотрении функционирования ИС, мы будем опираться только на анализ результатов полностью слитного, априорно неопределенного текстового потока (см. рис. 7б). В рамках рассматриваемого комплекса: ПО → ИК → ИС, задача ИС (см. рис. 2) заключается в: При этом, в саморазвивающихся ИС появляется дополнительное свойство - д) субъектность, которое проявляется в выборе более полезных для ИС процессов ПО (градуированной оценкой между "+" и "-", см. рис. 8). Блок субъектность эволюционно формируется в генетическую программу, управляющую начальным поведением ИС. Субъектность служит основанием для формирования оценки желательности или нежелательности любой семантической единицы (возможно даже очень сложной) для ИС (см. рис. 8). 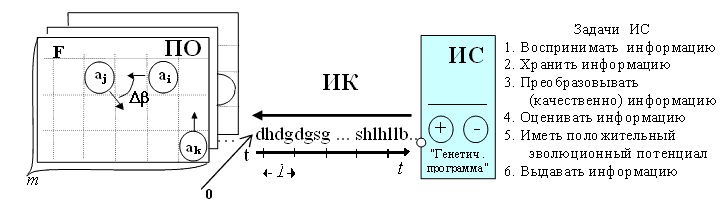 Рис. 8. Будем предполагать, что про ПО известно только то, что в любой из них выполняются:
Задача восприятия усложняется тем, что остальные характеристики ПО априорно не определены и, соответственно, в ИК даже не заданы какие-либо маркеры-подсказки, разделяющие ЭСЕ. Если в процессе квантования информационного потока на информационные единицы (образы) в памяти ИС не будет кратного вложения в них ЭСЕ, то потребность в ресурсе памяти ИС будет выражаться комбинаторными зависимостями от числа различных ЭСЕ в ПО и, в результате, невозможно будет построить практически ни одной ИС. Не решив эту задачу, классическое направление ИИ свелось к "игрушечным примерам". Таким образом, для эффективного решения задачи восприятия необходимо предварительно решить проблему автоструктуризации непрерывного информационного потока (ИК) на образы в ИС, кратные ЭСЕ (элементарным семантическим единицам) в ПО. Первым шагом по решению проблемы автоструктуризации стало расширение понятия формального нейрона МакКаллока-Питтса, вводом в него относительности времени активации входов, что позволило получить нейроподобный N-элемент (см. рис. 9), который работает в векторном пространстве образов и уже в единственном числе может отражать причинно-следственные процессы реальных физических ПО. 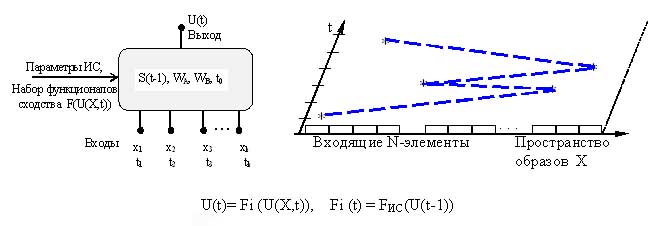 Рис. 9.
Схемами на базе из N-элементов можно моделировать любые логические схемы, включающие "и", "или", "не", но основное их предназначение - это структурированное хранение подпоследовательностей текстовых форм. Из N-элементов можно образовать послойные структуры (см. рис. 10), открывающие возможность иерархического построения памяти ИС. 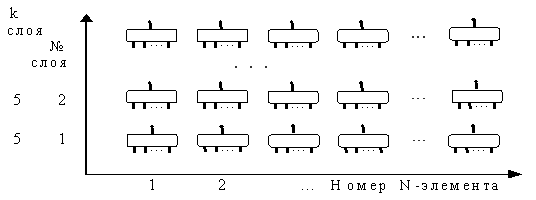 Рис. 10.
Объединив N-элементы в многодольный иерархический граф, удалось получить структуру, аналогичную естественно-языковым. Первый слой (доля графа) N-элементов – терминальный, фактически отображает алфавит А ЭСЕ, второй слой – "псевдослоги" и строится на пространственно-временных ссылках на предыдущий (терминальный) слой – информационное содержание N-элемента (см. рис. 9), слой "псевдослов" – ссылается на "псевдослоги" и т.д., до самого верхнего N-элемента, отображающего в себе через связи всю ПО (см. рис. 11). 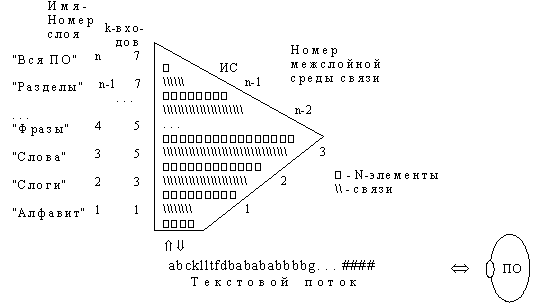 Рис. 11.
В зависимости от качества кратности вхождения ЭСЕ в образы, для памяти ИС требуется существенно различное число (М) N-элементов. Для лучшего и худшего случаев это соотношение характеризуется как: М и М3-:-5 [6]. Анализ информационного содержимого N-элементов в иерархической структуре НСС, в том числе и на тестовых ПО, показал, что при формировании ее алгоритмами, минимизирующими ее физический ресурс (RИС в битах), одновременно достигается свойство кратности (тождественности) образов и ЭСЕ.
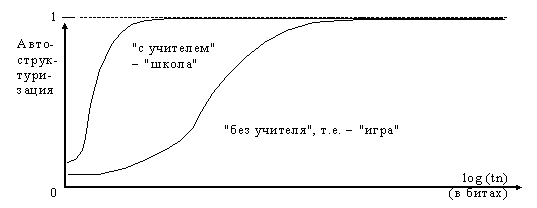
В работах [3,4,5] описаны алгоритмы автоструктуризации, которые из непрерывного, априорно неизвестного информационного потока эффективно выделяют отрезки текста, соответствующие семантическим единицам (ЭСЕ) исследуемой ПО. Например, уже начиная с 50 символьного отрезка - <ДОМЗЕБРЫСКИТНАДОМДОМВ НАДОМВСКИТВНАСКИТВВЗЕБРЫНАВНА>, на втором слое ИС правильно выделяются все ЭСЕ данной ПО в образы ИС: <ЗЕБРЫ> <СКИТ> <ДОМ> <НА> <В>. Все тестовые примеры при выполнении условий (1а и 1б) показывают 100% реализацию свойства автоструктуризации в рассмотренной ИС (см. рис. 11 и рис. 12). Для желающих почувствовать себя в роли ИС, можно попытаться выделить ЭСЕ из двух текстов, семантически тождественных вышеприведенному: Структуру памяти ИС, в которой выполняется свойство изоморфного отображения ЭСЕ ПО и их структуры в образы ИС и обратно, будем называть нейросемантической структурой (НСС). Т.е., если информационные содержания N-элементов ИС тождественны последовательной группе ЭСЕ, подчиняющимся принципу причинности и принципу подобия ПО (см. выше), то минимальную структуру (в битах) такой памяти ИС будем называть НСС (N-элемент « ЭСЕ+ЭСЕ+…+ЭСЕ). Минимизируя физическую ресурсоемкость памяти (RИС), мы автоматически получаем в ИС причинно-следственную структуру процессов ПО. НСС – это фактически готовая структура данных (процессов и объектов) произвольной ПО для любой ИС. Понятно, что автоматическое формирование НСС открывает широкие горизонты для инженерной практики при разработке различных АСУ. Назовем процесс формирования НСС – автоструктуризацией. НСС – это пример 1-го формального преобразования количественной (естественной) текстовой формы представления информации в качественную форму, в которой из континуальной (практически непрерывной, неструктурированной) текстовой формы образуется иерархическое множество образов данной ПО в виде многодольного графа, отображающего причинно-следственные связи образов (объектов-процессов) ПО. Качество самой НСС отображается отношением числа корректных пар (N-элемент « ЭСЕ) на общее число N-элементов ИС (НСС). Естественно, что в процессе автоматической подстройки ИС под конкретную, априорно неизвестную ПО, на начальном этапе ввода текстового потока "НСС-качество" невелико (<< 1), а далее, "НСС-качество" полностью зависит от алгоритмов ИС. На рис. 12 приведен характерный вид графика: "НСС-качество" – log (tn).
Рис. 12.
При достаточности текстового материала всегда достигаются величины "НСС-качество", близкие к 1. (Критерии достаточности: а) все возможное пространство состояний; б) если человек может правильно структурировать данный текстовой материал в непривычной форме записи; в) наличие характерных особенностей динамического процесса при минимизации ресурса RИС). Скорость автоструктуризации можно существенно улучшить, выделив и введя уже известные экспертам ЭСЕ "семантические затравки". Такой процесс автоструктуризации принято называть обучением "с учителем" (см. рис. 12). Полезность обучения "с учителем" хорошо известна для биологических ИС. В работе [2] исследовано и показано, что высокое качество автоструктуризации (N-элемент « ЭСЕ) является необходимым условием для запуска возможных самоорганизующихся процессов в ИС. Следует также отметить, что все технические характеристики памяти на базе НСС (время доступа, коэффициент компрессии-сжатия, надежность-пластичность хранения информации и др.) имеют тенденцию к улучшению, как в среднем, так и в абсолютных значениях по мере роста объема вводимой информации из ПО (см. рис. 13). Это пример второго эволюционного аттрактора самоорганизующихся ИС. 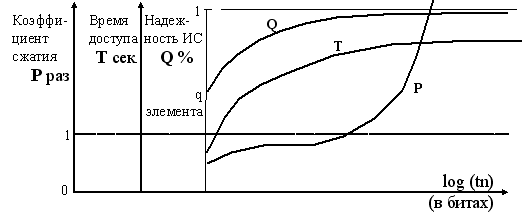 Предлагаемая модель нейроподобной структуры (см. рис. 11) функционально является более близкой к естественному прототипу - центральной нервной системе, чем современные модели нейронных сетей [1], за которыми исторически закрепилось направление нейрокомпьютинга. Особенности вышеперечисленных характеристик НСС являются основанием для построения на её базе крупномасштабной ассоциативной памяти (ИС), работающей со слабоструктурированными текстовыми потоками.
3. Интеллектуальное преобразование информационного ресурса (ИнфР) в ИС. Основной параметр задачи преобразования заключается в повышении компактности (компрессии) преобразуемого ИнфР в ИС, естественно, без потерь. На первом этапе эволюции ИС, ИнфР отображается только в фактографическую память ИС (см. рис. 11 и рис. 14). Имея генетически или конструктивно заложенное прагматическое отношение к конкретным ЭСЕ (<ожог-Х> – <боль-Ш>, <пища-С> – <ресурс-Е> и т.д.), ИС инстинктивно реагирует (<ожог-Х> – <движение-К> и т.д.), т.е., на каждое конкретное раздражение (Хi) – конкретная реакция (Уj). 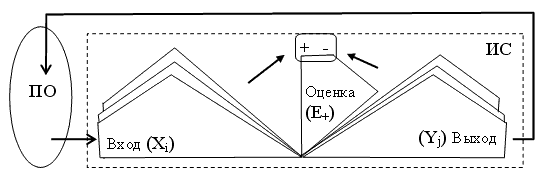 Рис. 14.
Иерархическая НСС интегрирует конкретные ЭСЕ в более крупные (по длине текстовой формы) или декомпозирует в более мелкие образы (см. рис. 11). При этом в НСС формируются как контекстные образы (иерархически более высокие причинно-следственные связи), так и ассоциативные образы (многократно входящие в вышележащие образы (так, например, слог-суффикс "КИЙ" – характеризует в русскоязычных текстах наличие определенного качества у ЭСЕ). Так, ассоциативность позволяет ИС выдвигать гипотезы о семантической связанности ЭСЕ, исходя из принципа структурного подобия. Таким образом, перемещаясь по НСС можно виртуально ("мысленно") путешествовать по всей ПО, причем, за счет ассоциативности и контекстности можно существенно расширить изначально заданные генетически программы "стимул-реакция" (см. рис. 14). На следующем этапе эволюции памяти ИС она строится уже как иерархическая структура из НСС. На фактографическую НСС настраивается НСС2 ("логическая"), которая функционально воспринимает НСС, также как НСС воспринимает ПО. При этом у ИС появляется возможность реагировать не на конкретные образы (ЭСЕ) ПО, а на определенные состояния N-элементов в НСС, вызываемые этими образами (ЭСЕ2) (см. рис. 15). 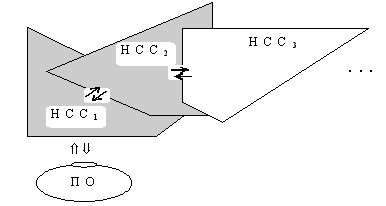 рис. 15.
Отметим, что механизмы иерархической организации НССi и НССi+1 регулярно однотипны, и это снимает возможные проблемы при организации полного цикла обработки информации. При этом, с ростом иерархии НСС уменьшается порог активации их N-элементов, что дает соответствующий приоритет этим вышестоящим структурам. Это конструктивное свойство нейросемантической ИС можно назвать - "приоритетом контекста". Его особенность заключается в дополнительной добавочной величине Uk(t) от выше расположенного "полуактивированного" (U(t)>0, т.е. распознающего) N-элемента, к U(t) N-элемента рассматриваемого слоя НСС (см. рис.9,10,11). Поясним примером. Допустим, что на вход ИС поступил образ "O". Это может быть и "буква – О", может быть "цифра – 0", а может быть и "геометрическая фигура". Типичный пример омонимии и полисемии (многозначности слов естественного языка). Если перед этим шли цифры, или "шел разговор" о математических дисциплинах, то распознаваемый образ в НСС будет воспринят как цифра – "0". Соответственно, если шел буквенный поток, то как буква – "О", если же "шел разговор" о геометрии или картографии, то как – "геометрическая фигура", и т.д. В случае же, если образ "O" идет первым в начале задачи, то его идентификация временно откладывается и уже последующие образы позволят извлечь его из оперативной памяти и "угадать". В НСС все "полуактивированные" N-элементы посылают по своим еще не активировавшимся связям "сигнал предвосхищения" – Uk(t), как бы "подсвечивая" всю контекстно ожидаемую область. Таким образом, "сигнал предвосхищения" становится решающим при многовариантном распознавании, практически снимая проблему полисемии (омонимии). Аналогичный механизм приоритета и при взаимодействии иерархии НСС. Реализация механизма контекста в нейросемантической ИС позволяет ей также удерживать "внимание" на решении одной задачи в сложных ПО. Конструктивно иерархия НСС устроена так, что у самой верхней НССС порог возбуждения ее N-элементов чуть более нуля и они случайным образом (спорадически) самовозбуждаются. (По нашим оценкам, 4-5-ти иерархических НСС вполне достаточно, чтобы моделировать основные психические функции человека). Информация в иерархию НСС поступает через НСС1. В НСС2 формируются "правила", в НСС3 – " правила правил". Чтобы между НССС и остальными НСС установилось функциональное взаимодействие, необходимы определенные требования к информационному потоку из ПО, а именно, в этом текстовом потоке должны отображаться "правила" и "правила правил" взаимодействия объектов и процессов ПО. Только в этом случае возможно существенное сжатие (компрессия) входных данных и контекстное (устойчивое) поведение ИС. Эмпирически дойдя до понимания этого, люди (социум ИС) в игровой форме стараются как можно быстрее обучением "прописать" связи в НСС2 и в НСС3 ("педагогика"). В процессе функционального соединения всех НСС, в верхних НСС формируются особые осциляторные структуры, контекстное управление которых начинает доминировать во всех информационных процессах ИС. Если ранее все процессы в НСС1 были детерминированы информационным потоком из ПО, то теперь ИС может что-то "не замечать" в ПО, или к чему-то "стремиться", не ухудшая при этом своих интегральных характеристик по E+. Свойство доминирования "внутренних (встречных)" информационных процессов (от НССС → НСС1, см. рис. 14 и 15) над "внешними" информационными процессами, идущими от НСС1, назовем сознанием ИС [5]. Рассматривая шкалу структур: НСС1 , НСС2, НСС3 , … , НССС, по функциональности обработки информации, мы видим (непрерывный) переход от "правополушарной" обработки информации к "левополушарной" в классификации психологов. Особенностью нейросемантической ИС является то, что обрабатываемые тексты ("задачи") и обрабатывающие тексты ("правила") представляются в ней в виде подструктур из N-элементов. В этих подструктурах, в рамках некоторого текущего контекста (N-элемента), и происходит слияние общепринятых понятий данные и алгоритм как неделимого пространственно-функционального элемента – образа. С одной стороны, реакции двух ИС в условиях тождества ПО (t, t-1, t-2, …, 0) также будут алгоритмически тождественны, исходя из принципа причинности. Но тождественных ПО в реальности не существует. Следовательно, практически мы не встретим двух тождественных реакций ИС (индивидуальность). С другой стороны, мы увидим целевую "разумность поведения" (реакций) всех ИС по параметру Е+. "Метаалгоритмом" этой общей целенаправленности поведения всех ИС будет асимптотическая (при t → ∞) минимизация отображения всех значимых для ИС текстовых потоков. "В природе все устроено так, что все нужное в ней компактно и красиво, а все ненужное – громоздко и безобразно". Во взаимопереводимости текстов "задач" и "правил" нейросемантической ИС прослеживается генетически связующая основа искусственного разума (ИP) и естественных языков (ЕЯ). Как в биологии: … организм → ДНК (текст) + ПО → организм → …, так и в языке: … ЕЯ → текст + ИС → ЕЯ → …, и, скорее всего, эта дуальность характерна для всех самоорганизующихся систем. p Формальная схема иерархического построения памяти ИС (см. рис. 15) уже не подпадает под запрет теоремы Гёделя о неполноте формальных систем на неограниченное познание открытых ПО. Так, если язык фактографической ИС (см. рис. 14) представляет только <X><Y><E+> (<стимул><реакция><оценка>), и, соответственно, имеет возможность описывать только конкретные пары <X><Y> с оценкой <E+>, то иерархическая схема в НСС2 (см. рис. 15) позволяет дополнительно (к <X><Y><E+>) описывать различные отношения R(<X><Y>) физических характеристик активируемых N-элементов (образов) с объединением всего этого оценкой <E+>.
Отметим, что максимальное число образов-траекторий, выявляемых в такой ИС, равно 1/6(5R+R3) от числа отношений R (см. приложение 1). Такой рекурсивный подход существенно расширяет первоначальный фактографический язык (НСС1), открывая неограниченную возможность ИС познания ПО. Этот пример третьего эволюционного аттрактора самоорганизующихся ИС демонстрирует кубическую нелинейность прироста возможности отображения ПО при линейных затратах ресурса ИС на R-отношения (Y=R(X), X=R-1(Y)). Интересно, что если взять всевозможные R-отношения реального физического мира во всем его многообразии, то мы получим структуру R-отношений, близкую к грамматикам естественных языков. Это свойство R-отношений, а также анализ корреляции смысловой близости слов с их относительными расстояниями в текстовом потоке могут быть положены в основу методики автоматической нормализации естественного языка, что может иметь большое значение для практики языкознания. В качестве примера использования R-отношений можно рассмотреть задачу - "формирование понятия 'абстрактного числа' в ИС" (неразрешимую для классического ИИ и легко решаемую биологическими ИС, как высшими животными, так и человеком). Одно из физических свойств N-элемента состоит в экспоненциальном падении величины возбуждения (U(t+1) = U(t) / t, например, при t=2) после его активации (U(t+1) = U(t) + 1*). На этом свойстве НСС построено функционирование ее в качестве кратковременной памяти (долговременная память НСС – это связи между N-элементами). Таким образом, если, например, в слое "псевдослов" некоторый N-элемент неоднократно активируется, то уровень активации (*) на нем будет в диапазоне 1*< U(t+1) < 2*. Если по другому информационному каналу (например, акустическому) будет активация N-элемента с информационным содержанием <два>, <три> или <семь>, то <два>, <три> или <семь> в НСС2 будут связаны с данной величиной U(t+1). И следующий раз, когда будет такое же число распознаваемых объектов (совершенно новых, например, "марсиан-гостей") – ИС выдаст реакцию, что их <два>, <три> или <семь>. Данным примером мы продемонстрировали один из основных принципов эволюции ИС от простейших форм до ИР – сведение информационных (семантических) характеристик ПО к физическим параметрам ИС, измеряемым в сантиметрах, битах, секундах (система СБС). Второй пример, адаптивные регуляторы (№1, №2, №3) на базе НСС. Запоминая пары <X><Y> и их оценку <E+> для любого априорно неизвестного объекта управления, регулятор №1 фактически перебором заполняет все возможное пространство его состояний. Затем, если ввести в рассмотрение и множество параметрических отношений R в парах <X><Y> как аналог "школьного образования", то, например, для перевернутого маятника, адаптивный регулятор №2 в парах быстро находит определенное отношение Ri (или их набор), которое дает <E+>. Так, для перевернутого маятника этими R-отношениями будут: Rj "разные знаки" (<X>*<Y> < 0 ), и Ri "величина реакции не меньше величины стимула" (<Y> ≥ <X>). Благодаря автоструктуризации, свойству кратковременной памяти и возможности выделения новизны, число попыток обучения адаптивного регулятора становится существенно меньше пространства его возможных состояний (см. график 1). На графике 1 представлен типичный пример соотношения скоростей обучения для адаптивного регулятора №2 (работает с НСС2) и регулятора №1 (память ИС не имеет иерархической структуры).
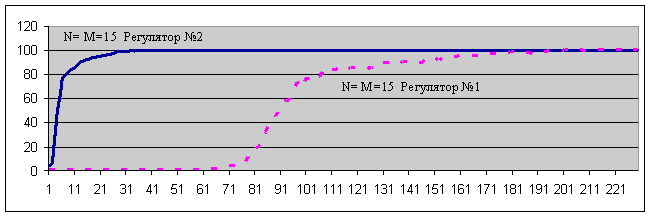 На графике (по оси абсцисс отложено число попыток обучения, по оси ординат – % правильных попыток-траекторий регулятора) видно, что эффективность обучения регулятора №2 много лучше чем у регулятора №1. Экспериментально показано, что при настройке управления на однотипные объекты, скорость обучения регулятора №2 не зависит от размерностей N и M (N – число состояний объекта, M – число состояний возможного управления, в эксперименте для простоты принималось N = M = 7,15,17,19,21), а определяется размерностью пространства R-отношений (которое обычно компактнее пространства управляемого объекта), тогда как у регулятора №1 она квадратичная (N*M – мощность пространства числа состояний управляемого объекта). Т.е., пример регулятора №2 демонстрирует возможность практического преодоления "проклятия размерности". На базе нейросемантического регулятора №3 формально показано, как на основе вышеописанных физических свойств N-элементов возможно естественное самоформирование R-отношений, представленных в регуляторе №2. Тем самым, подведено теоретическое основание для инженерного построения ИР, т.е. решение проблемы построения ИИ. Как и вычислительная техника, которая начала развиваться с теоретических моделей "машин Тьюринга и Поста", так и анализ работы нейросемантических регуляторов будет способствовать формированию широкого фронта научных работ по разработке ИР. Таким образом, на нейросемантическом регуляторе №1 можно продемонстрировать свойство "адаптационности", как возможность адаптироваться под любую априорно неизвестную ПО; на регуляторе №2 – "интеллектуальность", как возможность существенного сокращения перебора; и на регуляторе №3 – "разумность", как целенаправленное порождение нового знания. Завершая этот раздел, отметим, что в нем показано:
4. Дальнейшая интеллектуализация (как целенаправленное ограничение перебора) ИС на базе НСС. Научный аспект нейросемантического подхода также базируется на следующих основных принципах:
Предварительные работы показали, что психические понятия, обозначающие характер мыслительной деятельности биологических высокоорганизованных ИС: "понятно", "новое", "уже известно", "решение существует", "завершенное высказывание", "логическое высказывание" и многие другие, отображаются моделями типовых схем НСС. В частности, из приведенного списка рассмотрим два последних примера. Так, "завершенность высказывания" определяется величиной текстовой энтропии (ТЭ), характеризующей "семантическую меру" состояния контекста в НСС [2]. При ТЭ > 0,3, любое высказывание можно считать (с большой вероятностью) законченным, при ТЭ < 0,01 – незавершенным. Величина ТЭ конкретного образа, в свою очередь, считается по отклонению числа его использования (число связей вверх) от нормализованного числа ссылок данного слоя НСС. Текстовая энтропия. Для выделения ЭСЕ по их "частотной составляющей" можно использовать понятие текстовой энтропии (ТЭ) [2]. ТЭ построена таким образом, что если в текстом потоке, равном размеру пространства состояний (L*AL>), построенном на текстовых отрезках длины L, некоторый текст длины L встречается 1 раз, то его ТЭ = 1. Если всевозможные отрезки длины L на этом интервале (L*AL) встречаются ровно по одному разу, то ТЭ≡1 и этот текстовой поток представляет пример "белого шума" для текстовых отрезков длины L (см. рис. 3). Если текстовой поток представляет периодическую последовательность некоторого произвольного периода длины Т, то на его интервале в L*AL (при L=Т*n) получим ТЭ≡0. Для реальных текстов значение ТЭ как отдельных символьных последовательностей, так и всего потока находится в интервале от 0 до 1 (0 ≤£ ТЭ реального текста ≤1). См. рис. 16. 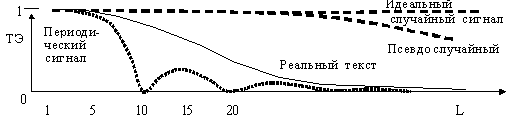 Рис. 16.
Если пространство возможных образов равных AL (см. рис. 3), сократить до реально отображаемых в ИС образов (<zbabj><jaabj>…<ezzjj>≤ AL), то мы получим величину относительной текстовой энтропии (ОТЭ). Ее особенность заключается в возможности порогового разделения семантически нагруженных и семантически пустых информационных потоков, см. рис. 17. 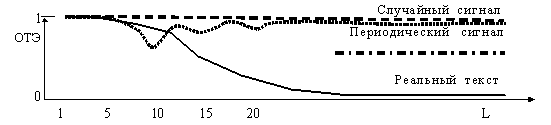 Рис. 17.
Таким образом, числовые значения ТЭ и ОТЭ являются эффективными параметрами-индикаторами, характеризующими возможность оперативного семантического анализа конкретной ПО (например, при поиске сигналов от внеземных цивилизаций). Проведенные нашей группой исследования текстов показали, что тексты можно разделить на два класса: "информационные" и "логические". Все завершенные "логические высказывания" обязательно содержат в своей текстовой форме повторения. Отсутствие же в высказывании повторений значимых образов (при анализе в НСС всех контекстов!) является примером чисто информационного высказывания (<Небо – голубое>), или индикатором алогичности (<В огороде бузина, а в Киеве дядька>). А, например, <большой объект (дом, …) закрывает маленький объект (дом, …)> – логическое высказывание. При замене же в нем одного из повторяющихся образов, например, получим <большая муха закрывает маленького слона> – такое высказывание уже нельзя считать не только логическим (нет повторений), но и даже завершенным по величине ТЭ полуактивированного контекста в НСС. Дальнейший анализ показал, что достаточно 2-х примеров, построенных по произвольному логическому правилу, и в НСС2 сформируется N-элемент, который при последующем получении незаконченного логического высказывания такого же типа, но уже с другими образами, завершает его с позиции данной ПО корректно. Так, например, на данных двух текстах в НСС1: |ВСЕ| |ВОЛК|И| |СЕР|Ы||А||ЕСТЬ| |ВОЛК|,||ЗНАЧИТ|,|А||ЕСТЬ| СЕР|ЫЙ|<E+> |ВСЕ||ПЕТУХ|И||КРАСИВ|Ы||В||ЕСТЬ||ПЕТУХ|,||ЗНАЧИТ|,|В||ЕСТЬ|КРАСИВ|ЫЙ|<E+> на кратно повторяющихся в НСС2 N-элементах строится логически завершенная подструктура:
где: Dti – N-элементы-детекторы ритмики "повторной" активации, Xi – "повторно" активирующиеся образы, знак "|" - обозначает найденные ИС границы между ЭСЕ. Рис. 18
Теперь, если на вход ИС поступает неполная фраза, например, <ВСЕ ВОЛКИ СЕРЫ А ЕСТЬ ВОЛК, ЗНАЧИТ, А ЕСТЬ >, то найдя в НСС1 ассоциативно ближайший N-элемент и активируя его, на выходе будет выдано - <СЕРЫЙ>. Напомним, что тексты: "ВСЕ ВОЛКИ СЕРЫ, А ЕСТЬ ВОЛК, ЗНАЧИТ, А ЕСТЬ СЕРЫЙ" (тексты в алфавите А)и $ДУЗ"ДРНМК"УЗТЭ."В"ЗУФЮ"ДРНМ."ЙП ВЩ КФ."В" ЗУФЮ"УЗТЭЛ$ (тексты в алфавите А-2 совершенно эквивалентны для нашей ИС, так как вторая текстовая последовательность получается из первой сдвигом номера символа в алфавите А на +2 (напомним, что для формирования правил-подструктур используются только данные, приведенные на рис.18). Если же на вход ИС поступает неполная фраза, например, < ВСЕ ПЛЮКИ КАНЫ, С ЕСТЬ ПЛЮК, ЗНАЧИТ, С ЕСТЬ >, то, не найдя в НСС1 ассоциативно близкого N-элемента (все меньше текущего порога), ИС включает на поиск ассоциаций НСС2. Здесь ассоциативно активизируется N-элемент, отображающий структуру, приведенную на рис. 18. Естественно, что у этого элемента нет полного сходства (U(t) <1) с текстом на входе. Поэтому, активируясь, этот N-элемент, задействует ритмические N-элементы (Dt), активируя до полноты все оставшиеся не активированные входы. В результате, на выходе ИС будет <КАНЫЙ> как итог активации N-элементов: Δt2 + Ы|Й. На фразу – <ВСЕ ЛЮДИ СМЕРТНЫ, СОКРАТ ЕСТЬ ЛЮД, ЗНАЧИТ, СОКРАТ ЕСТЬ>, ИС в своей "грамматике" выдаст: <СМЕРТНЫЙ>. Такую сложную информационную единицу (N-элемент) в НСС2 с полным правом можно назвать "знанием" о данной ПО. Вся Аристотелевская силлогистика укладывается всего в два десятка подобных правил, "человеческая" в 100-200 (!). Отметим, что "знание" позволяет еще более экономно расходовать память ИС. При обучении достаточно двух примеров, отображающих произвольные логические правила (условные рефлексы, алгоритмы и пр.), и далее ИС уже будет адекватно реагировать в форме текстового сообщения на все примеры, относящиеся к этому правилу, совершенно не расходуя при этом память ИС, являющуюся одним из основных ее ресурсов по значимости. Таким образом, все типы причинно-следственных (логических) текстов произвольной физической ПО покрываются (решаются) одним механизмом НСС (НСС2, НСС3, …). На каждое из рассмотренных типов психо-лингвистических понятий ("есть решение!", "не достаточно каких-то данных", "сильное решение", "узнал", "новое" и др.) у нас были найдены структуры из N-элементов, которые выполняли функцию правил-индикаторов. Есть большая уверенность, что и для других психологических понятий будут выявлены соответствующие им подструктуры в НСС. Постепенное, в процессе функционирования, (эволюционное) преобразование составляющих информационного ресурса: сигнала в информацию и информации в знание о ПО, при достаточных конструктивных механизмах ИС позволит ей полностью "понять" произвольную ПО и прогнозировать развитие в ней любых процессов со значением ТЭ → 0, т.е. с вероятностью прогноза 1.00. Процесс естественной эволюции обработки информации в ИС представляет ряд аттракторов, первый из которых ("рецепторный") мы рассмотрели в первом разделе. Второй эволюционный аттрактор ИС – "ассоциативный", заключается в переводе линейной формы памяти ИС в иерархически-сетевую. Здесь также, линейный рост объема запоминающего ресурса памяти ИС (нейроподобных элементов) будет приводить к экспоненциальному росту объемов отображаемой информации, что дает данному типу ИС дополнительные эволюционные преимущества (биологический аналог, животные, начиная с "рыб"). Третий аттрактор ИС – "интеллектуальный". Он позволяет сводить воспринимаемые семантические переменные текстов к константам их грамматических структур, отображаемых элементами памяти ИС (адаптивный регулятор №2, "высшие животные"). Конечное множество грамматических структур покрывает большую часть информационного потока любой предметной области. Четвертый эволюционный аттрактор ИС – "знание" (см. рис. 18), когда все типы грамматических конструкций ИС по переработке текста сводятся к 4-м конструкциям над грамматическими конструкциями ИС ("Homo-sapiens"). Попадая в каждый последующий эволюционный аттрактор, ИС увеличивает свой эволюционный потенциал (по все более крутой степенной функции отображения текстов среды в памяти ИС), существенно ускоряющего потенциальную скорость самокопирования. Скорость видообразования ИС пропорциональна количеству ИС в среде. Анализ показывает, что в рамках предложенной модели существует симбиоз различных стратегий ИС, пока не будет использован ("выеден") весь энергетический потенциал "текстовой вселенной" ("текстовая смерть" /zzz…z/ – аналог "тепловой смерти" вселенной). По мере роста дефицита энерго-вещественной компоненты среды число различных "видов" ИС будет сокращаться. В финале, у ИС остается только один "разумный" вариант – создание "Нового большого символьного взрыва" или его аналога ("Восхождение разума" [8]). Резюмируя выводы этого раздела, отметим, что в нем: 5. Заключение. Нашей группой, в течение последних пяти лет не было обнаружено принципиальных теоретических и инженерных ограничений и запретов на возможность построения ИP на базе НСС (нейросемантического подхода). Разработаны прототипы компьютерного интерфейса (человек-ИP), разрабатываются системы предварительной обработки информации (графической, акустической и др.), а также механизмы сопряжения текстовой формы представления информации с различными рецепторными и эффекторами каналами (задача г, выдача реакции ИС), см. рис. 19.
Рис. 19.
На базе структуры, представленной на рис. 19, разрабатывается несколько проектов: "Сценарий « видео ряд", "Картина « текстовое описание" и др. Для исследования и демонстрации эволюции информационных процессов от простейших ИС и до человека (социальные формы обучения) разработан адаптивный нейросемантический регулятор [6,7]. В МФТИ читается курс "Введение в нейросемантику" и готовятся к публикации методические материалы. По нашим оценкам, вполне возможно через 12 месяцев получить программную реализацию вышеописанного ИP. Далее, за 18 и 24 месяца, на базе многопроцессорных ЭВМ (256-1024 RISC процессоров) можно сформировать многопроцессорный кластер и чисто аппаратную реализации ИP, реализуя естественную параллельность процессов в НСС. Перспективы появления в нашей жизни ИP грандиозны. Это ускорение на 6-9 порядков скорости решения любых "интеллектуальных" задач с одновременным повышением их сложности (числа компонент) на 5-6 порядков. Это появление новой парадигмы обработки информации и разработка на ее базе принципиально новой аппаратуры, отражающей следующий этап эволюции технических ИС. При этом будет возможен перенос новых принципов мышления как в педагогику, так и создание новых алгоритмов на классические "фон-неймановские калькуляторы" (например, механизмы счета людей "чудо-счетчиков"). Для нашей цивилизации появление ИP - это реальный шанс ее светлого будущего, но также и возможность ее трагического финала, особенно в сегодняшнее неуправляемое время "технологий глобального (воз)действия" (биотехнологий, информационных, нанотехнологий, ядерных, финансовых и др.), которые, попав в руки террористов, превращаются в орудие ада. Без ИP человечеству в 21 веке практически не выжить и в подтверждение этого тезиса можно привести множество доводов [8,9]. Основной причиной всех социальных и прочих, вытекающих из них конфликтов, является "парадокс Рассела в социуме" (принцип "двойных стандартов" на групповом, общественном и на межгосударственных уровнях) [2]. Сущность "парадокса Рассела в социуме" заключается в логической невозможности управляющего субъекта одинаково (справедливо) управлять самим собой и обществом таких же как и он субъектов. В результате, эгоизм управляющей ИС субъективно навязывается обществу всех ИС. Рождается почва для различных эгоистических конфликтов, которые формируют множество внутренних антагонистических фронтов, поглощающих львиную долю всех значимых для ИС ресурсов общества. Включение ИР в сферу социального управления теоретически устраняет все основания для проявления и существования "парадокса Рассела в социуме", тем самым, выводя социальное развитие на устойчивый экспоненциальный уровень – пятый эволюционный аттрактор (ноосферу). В основе пятого эволюционного аттрактора (автокаталитического, социального) лежат системные законы, открытые А.А.Богдановым в его знаменитой "Тектологии" [10]. Еще в 1911 году он показал, что результирующая сумма системы по какому-либо параметру существенно зависит от характера направленности взаимодействия составляющих ее подсистем. Так, в случае целевой согласованности всех подсистем, суммарный результат системы получается больше, чем простая сумма результатов отдельных подсистем ("Закон сверхаддитивности"). Осознание факта проявления в социуме "парадокса Рассела" и "Закона сверхаддитивности", требует включения ИР в социально-экономическое управление обществом, что позволит человечеству преодолеть надвигающееся смутное время надвигающегося хаоса "технологий глобального воздействия" [9]. Человечество вступило в фазу своего развития, когда у нее образовался избыток человеческого ресурса. Сегодня у цивилизации нет масштабной необходимости в "строителях пирамид" и "рабах для хлопковых плантаций". Сменился приоритет задач, да и автоматы вышеназванные работы выполняют лучше. Цивилизация не может целенаправить 4/5 своего ресурса, и предоставленные сами по себе они скатываются в метастазы терроризма. Основная эволюционно значимая характеристика человека - это порождение нового знания. Каждый человек, в той или иной мере, способен творить новое. Но очень часто энтузиасту не под силу реализовывать большие проекты без посторонней интеллектуальной и материальной помощи. А где ее взять, если в проекте кроме него самого, никто больше не заинтересован? И здесь на помощь творцу и придет ИР (Интеллектуальное рабочее место исследователя - ИРМИ) со своей громадной базой знаний (1018-1024 байт) и, как следствие, с большими инструментальными возможностями [8]. ИРМИ в рамках Российского центра поддержки инноваций (проект "Информоград") каждому исследователю даст в свое распоряжение колоссальные материальные и интеллектуальные возможности, о которых до этого не могли мечтать и целые государства. В процессе взаимодействия при решении задачи, ИРМИ помогает человеку получить новое решение, человек при этом обучает ИР, представляя ему уже известные знания. Новое же знание, полученное в ходе сотрудничества ИРМИ и человека, становится их общим знанием, взаимообогащая их обоих, как бы более интеллектуально ИР не превосходил человека. Шестой эволюционный аттрактор – "Восхождение разума", интеграция всех форм ИС, независимо от их начальной природы. Отметим, что для того, чтобы ИС могла войти в каждый последующий эволюционный аттрактор, она предварительно должна соответственно усложнить свою структуру, и так идя по всей эволюционной цепочки аттракторов, начиная с самого первого. Страхи, что ИР поработит человечество – типичный пример широко распространившегося шаманизма от киноиндустрии. Для человека более опасен другой человек, т.к. у них одна ниша потребления. Генетически же ИР нацелен на космос, именно там широкое поле для его деятельности. Неограниченное количество любых материальных ресурсов вселенной не дает даже теоретических основ для конфликта между ИР с земным человеком. С точки же зрения сотрудничества, ИР для человека представляется идеальным партнером, т.к. у них одна область производства легко тиражируемого результата, где, в итоге, каждый получает весь конечный продукт – новое знание (пример ИРМИ). Так что, никаких естественных оснований для конфликта между человеком и ИР нет. Сотрудничество же человека с ИР станет мощным стимулом для нового экспоненциального этапа научно-технического прогресса нашей цивилизации. Работы над созданием ИР должны проводиться только в рамках нового гуманистического мировоззрения и специализированной международной академической инфраструктуры. Это необходимо и для того, чтобы такой фактор, как ИР не стал "информационной дубиной" в руках какой-либо эгоистической группировки. В качестве начальной социально-экономической структуры по разработке ИP предлагается проект "Информоград" [2,9]. Если, ретроспективно рассмотрев в данном материале процесс-траекторию эволюции ИС от "венца творения" до простейших (см. рис. 1 и 2), у Вас осталось желание проанализировать перспективу как нам сегодняшним Homo-sapiens подняться к 2030 году до "Сверхразума", то, пожалуйста, посмотрите проект "Информоград" [9] и присоединяйтесь к разработчикам по его воплощению в жизнь. Резюмируя выводы заключительного раздела "Концепции построения искусственного разума", отметим:
Список литературы
|
|||||||||||||||||||||
|
© Морозевич Ю. В.,
Москва, 2008 |