ЛИНГВИСТИЧЕСКИЕ
ОСНОВЫ ДЛЯ ФОРМИРОВАНИЯ
На рубеже XX и XXI вв., основной, определяющей характеристикой развития человечества в информационной области, по-видимому, будет повсеместная интеграция средств информатики не только в национальных границах, но и в международном плане. Автоматизированный перевод можно рассматривать как один из способов создания многоязычного интерфейса и тезауруса.
На пути машинного перевода стоят огромные трудности, которые отнюдь не уменьшающиеся с бурным развитием кибернетики, хотя лет 10 назад большинство специалистов рисовали самые радужные перспективы на самое ближайшее будущее, но задача оказалась на много сложнее чем это ожидалось в начале.
Человеческий мозг по своей сложности и мощности на несколько порядков превышает современные ЭВМ. В ходе эволюции у мозга выработалась специализация - это распознавание образов и речи. Что касается работы мозга по переводу с одного языка на другой - это сложнейшая интеллектуальная работа, весьма слабо реализованная в существующих программах. Проблемы автоматического перевода прежде связано со сложностью задачи (многовариантность перевода, для правильности которого мозг человека учитывает весь свой предыдущий жизненный опыт). Одна из лучших современных программ, ориентированных на рынок ПК, является система автоматического перевода Stylus. Но только создание программ, обладающих зачатками искусственного интеллекта, позволит окончательно решить эту задачу. По этому пути и пошли лучшие программисты, создающие современные программы для перевода (естественно, в относительно узких рамках данной задачи). Подобные программы строятся на так называемых развивающихся алгоритмах, в частности, нейронных сетях.
Предложения нашей группы
по распознаванию текста и его автоматизированному переводу основано на базе нейросемантической парадигмы (НСС) и состоит из четырех этапов [1].Первый этап
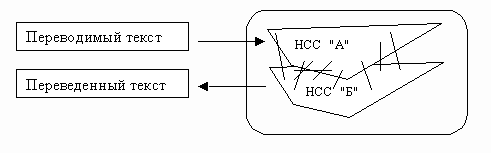
- это построение нейросемантического пространства переводимых предметных областей. Для примера рассмотрим два языка "А" и "Б". Всевозможные текстовые материалы предметных областей на языках "А" и "Б" вводятся в НСС, автоматически преобразуясь два многомерных гипертекстовый НСС-графа: НСС-"А" и НСС-"Б".Скорость преобразования неподготовленных текстов на языках "А" и "Б" ~ 0,2 -1 Кбайт/сек. При этом, ввод одного Гбайта текстов (тезаурус в ~ 100 тыс. статей "А" и "Б"), формирующего достаточное нейросемантическое пространство для однозначной идентификации текстовых сообщений займет несколько месяцев Проекта.
Второй этап - установление семантического соответствия слов, фраз (образов) между предметными областями языков "А" и "Б", представленными гипертекстовыми графами НСС- "А" и НСС- "Б".
Этот этап соответствует основному механизму современных автоматизированных систем перевода, которые используют словари соответствия слов и фраз между языками "А" и "Б". Используя уже наработанные словари соответствия связываются вершины гипертекстовых граф НСС-"А" и НСС- "Б". Ориентировочное время выполнения этого этапа Проекта ~ один месяц. Таким образом, через месяц, прототип системы автоматизированного перевода информации одной предметной области из дного языка в другой ("А" ® "Б" или "Б" ¬ "А" ) построена.
Третий этап - обучение НСС грамматическим правилам перевода и введение базы известных правил. Задавая опорные пары примеров перевода: "текст на языке `А` и перевод этого текста на языке `Б` " в НСС осуществляется формирование НСС-структур, соответствующих грамматическим правилам перевода между языками "А" и "Б". После анализа и удовлетворительного тестирования лингвистами-переводчиками результатов НСС перевода, проект "Интерлингва" можно считать выполненным.
Общее время выполнения Проекта по НСС технологии ~ 12-18 месяцев.
Четвертый этап - перевод. Принцип работы системы НСС-перевода заключается во вводе переводимого текста относящегося к заданной предметной области на языке ("А" или "Б" ) в соответствующий ему НСС-граф ("А" или "Б" ). При этом, в НСС-графе идет постоянный контроль однозначности "понимания" вводимого текста. В случае неоднозначности (активация более одной вершины в графе НСС, например, НСС-"А"), необходимо расширить контекст переводимого текста введением дополнительной информации, до однозначной идентификации. Отметим, что для текстов более 1 Кбайт, однозначность идентификации достигается практичиски в 100% случаев.
Общая схема функционирования системы НСС-перевода.
Параллельно процессу идентификации, через через дуги семантического соответствия в смежном графе НСС (например, НСС-"Б"), также происходит процесс идентификации, но уже на другом языке. В случае однозначности "понимания" на другом языке, можно считать перевод выполненным.
Так как результат перевода в НСС конструируется из фраз на языке перевода, плюс дополнительное связующее сглаживание фраз, которое осуществляется способностью НСС обучаться на примерах, все это дает возможность достигать 100% точности автоматического перевода с одного языка на другой. Скорость перевода соответствует скорости ввода информации при построении нейросемантического пространства на первом этапе Проекта.
Для желающих более подробно ознакомиться с бизнес-планом Проекта, см. "Бизнес-план разработки системы НСС-перевода".
E-mail: BODY@IPU.RSSI.RU
Понятно, что на базе предлагаемого Проекта можно начать целые направления в распознавании образов и в лингвистике: по распознаванию устной речи, по распознаванию рукописного текста, а также по формированию универсального языка (Линкоса) и др.
ã Группа Информоград 2001



